运维文档
Centos7运维命令
Centos7使用阿里云yum源
Centos7 Yum相关软件在线安装
Windows运维
工具类运维
禅道系统运维
git使用培训
Mysql运维
MySQL 索引
Mysql模拟故障恢复案例过程
使用mysqldump对数据库定时备份脚本
常用Sql
Git常用操作命令
搭建ZSK服务
SVN常用操作命令及维护
Ubuntu相关运维
gitlab安装升级操作
常用统计SQL-治未病
服务人数-活动档案统计
Oracle数据库管理
Windows安装VC2015\VC2017
Idea离线开发的Maven设置
慢病治未病部署步骤
Centos7升级openssh+openssl
Centos7 ISO文件做本地yum源
使用mkcert生成自签名证书
OpenEuler
openEuler运维命令
OpenEuler22.03源码编译安装Nginx
OpenEuler安装docker
Docker
Centos7在线搭建docker的elasticsearch环境(单节点)
Docker搭建Hadoop环境
Docker搭建Hadoop环境(新)
Docker维护命令
Docker启动minIO
常用工具或软件的Docker启动命令
Word中查找和替换通配符用法介绍(完全版)
PostgreSql安装与配置
安装Debian10系统
量表扩展信息字段说明
Debian在线安装软件以及修改源
windows本地连接openclaw的UI界面
本文档使用 MrDoc 发布
-
+
首页
MySQL 索引
# MySQL 索引 引用:[Mysql 索引](https://www.cnblogs.com/juno3550/p/14865167.html "Mysql 索引") ## 前言 生产上为了高效地查询数据库中的数据,我们常常会给表中的字段添加索引。那么如何添加索引才能使索引更高效: - 添加的索引是越多越好吗? - 索引有哪些类型? - 为啥有时候明明添加了索引却不生效? - 如何评判一个索引设计的好坏? 针对上述问题,本文将会从以下几个方面来讲述索引的相关知识: 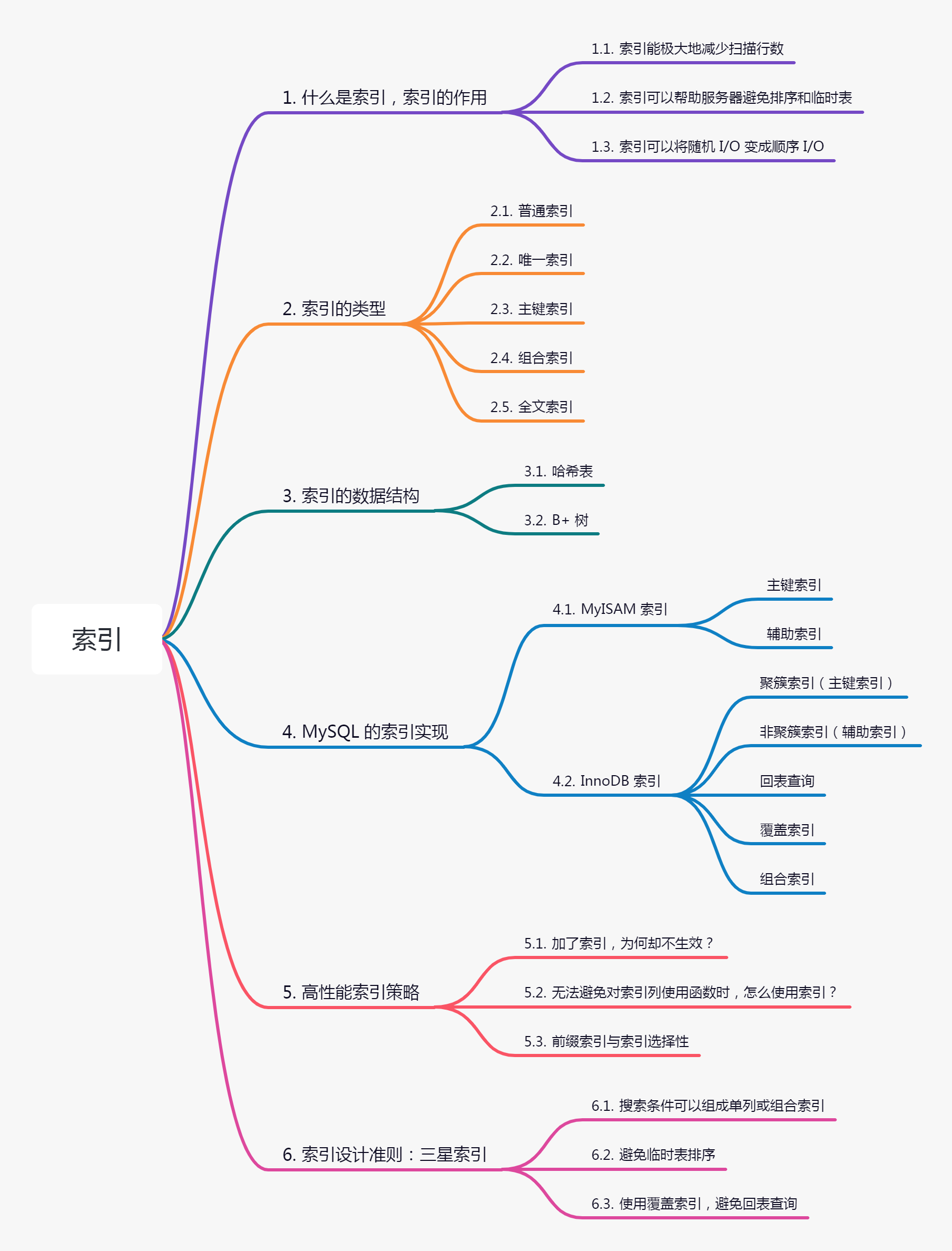 ## 1. 什么是索引,索引的作用 ==索引是对数据库表中一列或多列的值进行排序的一种数据结构==,好比是一本书前面的目录,可以增加对特定信息的查询速度。 一般来说索引本身也很大,不可能全部存储在内存中,因此==索引往往是存储在磁盘上的文件==中的(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。 ### 1.1 索引能极大地减少扫描行数 当我们要在新华字典里查某个字(如「先」)具体含义的时候,通常都会拿起一本新华字典来查,你可以先从头到尾查询每一页是否有「先」这个字,这样做(对应数据库中的全表扫描)确实能找到,但效率无疑是非常低下的,更高效的方法相信大家也都知道,就是在首页的索引里先查找「先」对应的页数,然后直接跳到相应的页面查找,这样查询时间大大减少了,可以是 O(1)。  数据库中的索引也是类似的,通过索引定位到要读取的页,大大减少了需要扫描的行数,能极大地提升效率。简而言之,索引主要有以下几个作用: 1. 即上述所说,索引能==极大地减少扫描行数==。 2. 索引可以帮助服务器==避免排序和临时表==。 3. 索引可以将==随机 IO== 变成==顺序 IO==。 第一点上文已经解释了,我们来看下第二点和第三点。 ### 1.2 索引可以帮助服务器避免排序和临时表 先来看第二点,假设我们不用索引,试想运行如下语句: ```sql select * from user order by age desc; ``` MySQL 的执行流程是这样的:扫描所有行,把所有行加载到内存后,按 age 排序生成一张临时表,再把这表结果返回给客户端。更糟的情况是,如果这张临时表的大小大于 tmp_table_size 的值(默认为 16 M),内存临时表会转为磁盘临时表,性能会更差。 如果加了索引,因为索引本身是有序的,所以从磁盘读的行数据本身就是按 age 排序好的,也就不会生成临时表(空间消耗)和额外排序(CPU 消耗),无疑提升了性能。 ### 1.3 索引可以将随机 I/O 变成顺序 I/O 再来看随机 I/O 和顺序 I/O,先来解释下这两个概念。相信不少人应该吃过旋转火锅,服务员把一盘盘的菜放在旋转传输带上,然后等到这些菜转到我们面前,我们就可以拿到菜了。假设转一圈需要 4 分钟,则最短等待时间是 0(即菜就在你跟前),最长等待时间是 4 分钟(菜刚好在你跟前错过),那么平均等待时间即为 2 分钟。假设我们现在要拿四盘菜,这四盘菜==随机分配==在传输带上,则可知拿到这四盘菜的平均等待时间是 8 分钟(随机 I/O),如果这四盘菜刚好紧邻着排在一起,则等待时间只需 2 分钟(顺序 I/O)。  上述中传输带就类比磁道,磁道上的菜就类比==扇区(sector)==中的信息,扇区是硬盘读写的基本单位;而==磁盘块(block)==是由多个相邻的扇区组成的,是==操作系统读取的最小单元==。这样如果信息能以 block 的形式聚集在一起,就能极大减少磁盘 I/O 时间,这就是顺序 I/O 带来的性能提升,下文中我们将会看到 B+ 树索引就起到这样的作用。 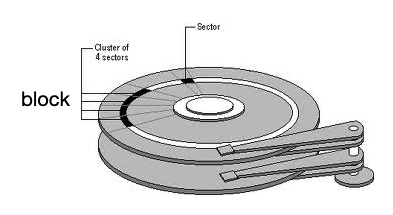 > 如上图所示:多个扇区组成了一个 block,如果要读的信息都在这个 block 中,则只需一次 I/O 读 而如果信息在一个磁道中分散地分布在各个扇区中,或者分布在不同磁道的扇区上(寻道时间是随机 I/O 主要瓶颈所在),将会造成随机 I/O,影响性能。 我们来看一下一个随机 I/O 的时间分布:  1. Seek Time(寻道时间):磁头移动到扇区所在的磁道。 2. Rotational Latency(旋转时延):完成步骤 1 后,磁头移动到同一磁道扇区对应的位置所需求时间。 3. Transfer Time(传输时间):从磁盘读取信息传入内存时间。 MySQL 的数据是一行行存储在磁盘上的,并且这些数据并非物理连续地存储,这样的话要查找数据就无法避免随机在磁盘上读取和写入数据。对于 MySQL 来说,当出现大量磁盘随机 I/O 时,大部分时间都被浪费到寻道上(大概占据随机 I/O 时间的 40%)。 随机 I/O 和顺序 I/O 大概相差百倍 (随机 I/O:10 ms/ page,顺序 I/O:0.1ms / page),可见顺序 I/O 性能之高,索引带来的性能提升显而易见! #### 由 MySQL 优化器做选择 注意,即使 SQL 完全符合索引生效的场景,考虑到实际数据量等原因,最终是否使用索引还要看 MySQL 优化器判断全表扫描和走索引的成本哪个更低(当然也可以在 SQL 中写明强制走某个索引)。 #### 建立索引也有不好之处 1. 索引需要占用物理空间,因此也增加了磁盘存储空间。 2. 索引虽然会提高查询效率,但是会降低更新表的效率。比如每次对表进行增删改操作,MySQL 不仅要保存数据,还要保存或者更新对应的索引文件。 也就是说==创建索引和维护索引要耗费空间和时间,这种耗费随着数据量的增加而增加==,因此索引也不是越多越好,在数据量小的情况下则没必要建索引。 #### 索引不适合的场景 - 数据量少 - 数据更新频繁 - 区分度低的字段(如性别) ## 2. 索引的类型 ### 索引类型 - 单列索引:即一个索引只包含单个列。一个表可以有多个单列索引,但这不是组合索引。 - 联合索引:即一个索引包含多个列。 - 普通索引/二级索引(INDEX/KEY):最基本的索引,没有任何限制。 - 唯一索引(UNIQUE):与“普通索引”类似,不同的是:索引列的值必须唯一,但允许有 NULL。 - 主键索引(PRIMARY):一种特殊的唯一索引,不允许为 NULL。 - 全文索引(FULLTEXT):仅可用于 MyISAM 表, 主要用于在长篇文章中检索关键字信息。针对较大的数据,生成全文索引很耗时好空间。 ### Mysql 索引语法 创建索引 ```sql CREATE TABLE table_name[col_name data type][unique|fulltext][index|key][index_name](col_name[length])[asc|desc] ``` 参数介绍: - **unique|fulltext** 为可选参数,分别表示唯一索引、全文索引。 - **index** 和 **key** 为同义词,两者作用相同,用来指定创建索引。 - **col_name** 为需要创建索引的字段列,该列必须从数据表中该定义的多个列中选择。 - **index_name** 指定索引的名称,为可选参数,如果不指定,默认 col_name 为索引值。 - **length** 为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度。 - **asc** 或 **desc** 指定升序或降序的索引值存储。 #### 查看索引 ```sql -- 方式1 show index from `table_name`; -- 方式2 show keys from `table_name`; ``` 查询结果字段解释: - Table:表的名称。 - Non_unique:如果索引不能包括重复词,则为 0;如果可以,则为 1。 - Key_name:索引的名称。 - Seq_in_index:索引中的列序号,从 1 开始。 - Column_name:列名称。 - Collation:列以什么方式存储在索引中。在 MySQL 中,有“A”(升序)或“NULL”(无分类)。 - Cardinality:索引中唯一值的数目的估计值。通过运行 ANALYZE TABLE 或 myisamchk -a 可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL 使用该索引的机 会就越大。 - Sub_part:如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为 NULL。 - Packed:指示关键字如何被压缩。如果没有被压缩,则为 NULL。 - Null:如果列含有 NULL,则含有 YES;如果没有,则该列含有 NO。 - Index_type:用过的索引方法(BTREE、FULLTEXT、HASH、RTREE)。 #### 删除索引 ```sql -- 方式1 ALTER TABLE `table_name` DROP INDEX index_name; -- 方式2 drop INDEX indexname on `table_name`; ```
张文海
2023年9月8日 11:31
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码